Fleur base restart workchain
Current version: 0.1.1
Class:
FleurBaseWorkChainString to pass to the
WorkflowFactory():fleur.baseWorkflow type: Technical
Aim: Automatically resubmits a FleurCalculation in case of failure
Computational demand: Corresponding to a single
FleurCalculationDatabase footprint: Links to the FleurCalculation output nodes and full provenance
File repository footprint: no addition to the
CalcJobrun
Contents
Import Example:
from aiida_fleur.workflows.base_fleur import FleurBaseWorkChain
#or
WorkflowFactory('fleur.base')
Description/Purpose
This workchain wraps FleurCalculation
into BaseRestartWorkChain
workchain, which is a plain copy of a BaseRestartWorkChain originally implemented in
AiiDA-QE. The workchain automatically
tracks and fixes crashes of the FleurCalculation.
Note
This workchain accepts all of the inputs that is needed for the FleurCalculation. It also contains all the links of the outputs generated by the FleurCalculation. It most of the cases, a user does not feel the difference in the front-end behaviour between FleurCalculation and FleurBaseWorkChain.
The workchain works as follows:
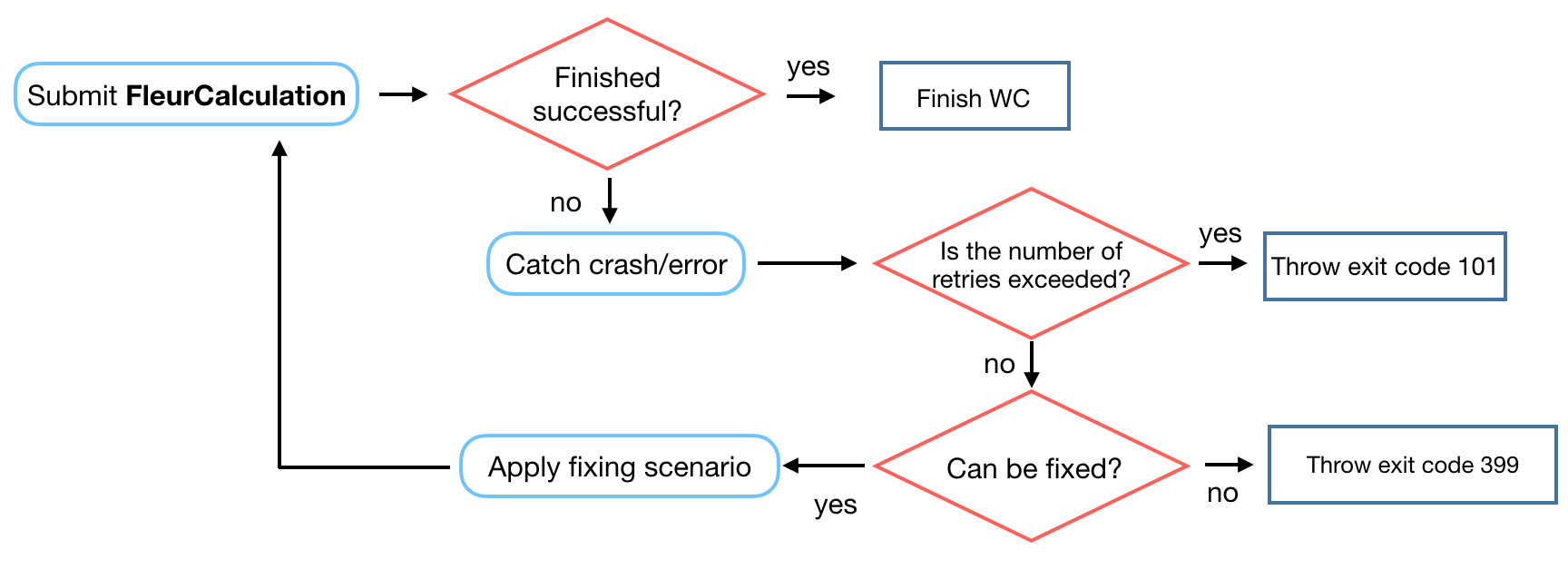
For now only problems with memory can be fixed in
FleurBaseWorkChain
:if a FleurCalculation finishes with exit status 310
the FleurBaseWorkChain will resubmit it setting twice larger number of computational nodes.
Warning
The exit status 310 can be thrown only in a few tested cases. Different machines and different compilers can report the memory issue in various ways. Now only a few kinds of reports are supported:
‘Out Of Memory’ or ‘cgroup out-of-memory handler’ string found in out.error file.
If memory consumption, which is printed out in out.error as ‘used’ or in usage.json as ‘VmPeak’, is larger than 93% of memory available (printed out into out.xml as memoryPerNode).
All other possible memory issue reports are not implemented - please contact to the AiiDA-Fleur developers to add new report message.
check_kpts() method
Fixing failed calculations is not the only task of
FleurBaseWorkChain. It also implements automatic
parallelisation routine called
check_kpts(). The task of this
method is to ensure the perfect k-point parallelisation of the FLEUR code.
It tries to set up the number of nodes and mpi tasks in a way that the total number of used MPI
tasks is
a factor of the total number of k-points. Therefore a user actually specifies not the actual
resources to be used in a calculation but their maximum possible values.
The optimize_calc_options(), which is used by
check_kpts(), has five main inputs:
maximal number of nodes, first guess for a number of MPI tasks per node, first guess for a number
of OMP threads per MPI task, required MPI_per_node / OMP_per_MPI ratio and finally, a
switch that sets up if OMP parallelisation is needed. A user does not have to use
the optimize_calc_options() explicitly, it will
be run automatically taking options['resources'] specified by user. nodes input
(maximal number of nodes that can be used) is taken from "num_machines".
mpi_per_node is copied
from "num_mpiprocs_per_machine" and omp_per_mpi is taken from "num_cores_per_mpiproc"
if the latter is given. In this case use_omp is set to True
(calculation will use OMP threading),
mpi_omp_ratio will be set to "num_mpiprocs_per_machine" / "num_cores_per_mpiproc"
and number of
available CPUs per node is calculated as "num_mpiprocs_per_machine" * "num_cores_per_mpiproc".
In other case, when "num_cores_per_mpiproc" is not given, use_omp is set to False and
the number of available CPUs per node is assumed to be equal to "num_mpiprocs_per_machine" and
mpi_omp_ratio will be ignored.
Note
The error handler, which is responsible for dealing with memory issues, tries to decrease the
MPI_per_node / OMP_per_MPI ratio and additionally decreases the value passed to
mpi_omp_ratio by the factor of 0.5.
Note
Before setting the actual resources to the calculation,
check_kpts() can throw an
exit code if the suggested load of each node is smaller than 60% of what specified by user.
For example, if user specifies:
options = {'resources' : {"num_machines": 4, "num_mpiprocs_per_machine" : 24}
and check_kpts() suggested to
use 4 num_machines and 13 num_mpiprocs_per_machine the exit code will be thrown and
calculation will not be submitted.
Warning
This method works with PBS-like schedulers only and if num_machines and
num_mpiprocs_per_machine are specified. Thus it method can be updated/deprecated for
other schedulers and situations. Please feel free to write an issue on this arguable
function.
Errors
Exit code |
Reason |
|---|---|
101 |
Maximum number of fixing an error is exceeded |
102 |
The calculation failed for an unknown reason, twice in a row This should probably never happen since there is a 399 exit code |
360 |
|
389 |
FLEUR calculation failed due to memory issue and it can not be solved for this scheduler |
Exit codes duplicating FleurCalculation exit codes:
Exit code |
Reason |
|---|---|
311 |
FleurCalculation failed because an atom spilled to the vacuum during relaxation. |
312 |
FleurCalculation failed due to MT overlap. |
399 |
FleurCalculation failed and FleurBaseWorkChain has no strategy to resolve this |